A primer on GraphEM#
Expected time to run through: 60 mins
This tutorial introduces the basics of the GraphEM method with a pseudoproxy reconstruction experiment, leveraging a proxy system modeling based emulation of the PAGES 2k version 2 database, with the realistic spatial and temporal availabilities. The pseudoproxies are generated based on the original iCESM simulated surface temperature (tas) without noise. While with LMR it is advantageous to have many redundant proxies (as long as they are unbiased, which is the case here), with GraphEM this
can lead to some counter-intuitive difficulties, which we explain below.
[1]:
%load_ext autoreload
%autoreload 2
import cfr
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import gridspec
Data Preparation#
[2]:
# load a proxy database
job = cfr.ReconJob()
job.load_proxydb('pseudoPAGES2k/ppwn_SNRinf_rta')
[3]:
# filter the database
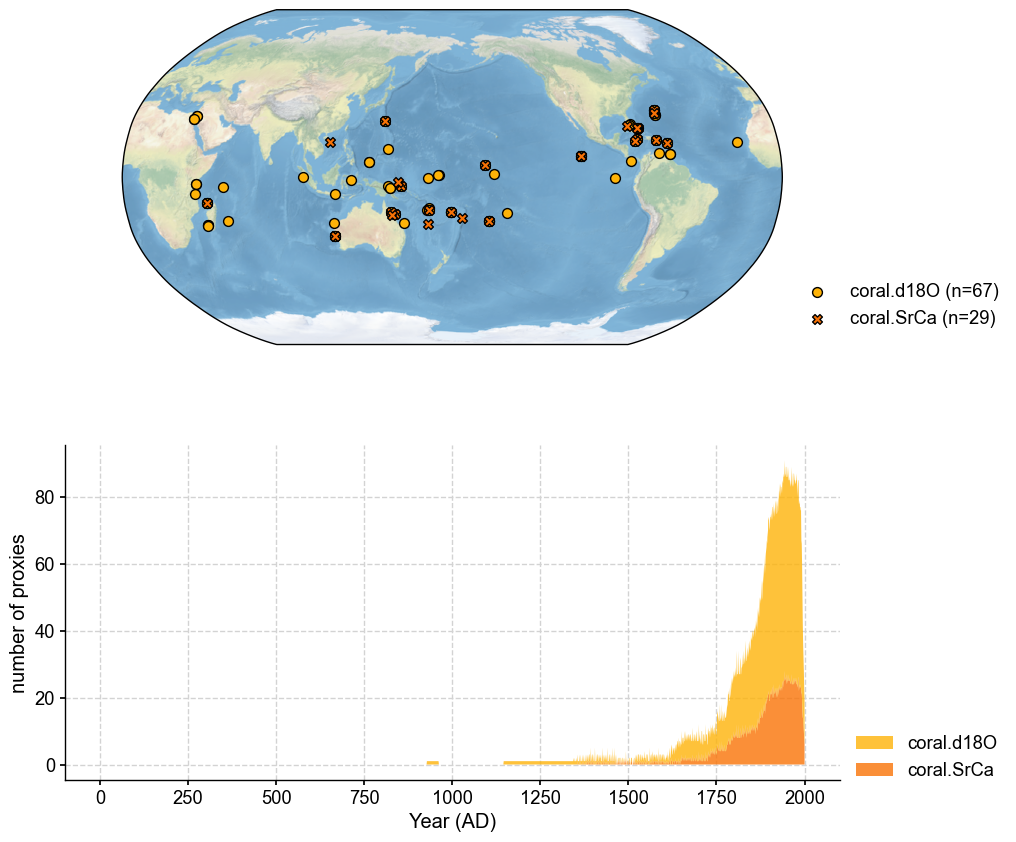
job.proxydb = job.proxydb.filter(by='ptype', keys='coral')
fig, ax = job.proxydb.plot(plot_count=True)
[7]:
job.annualize_proxydb(months=[12, 1, 2], verbose=True)
>>> job.configs["annualize_proxydb_months"] = [12, 1, 2]
>>> job.configs["annualize_proxydb_ptypes"] = {'coral.SrCa', 'coral.d18O'}
Annualizing ProxyDatabase: 100%|██████████| 96/96 [00:03<00:00, 28.36it/s]
>>> 96 records remaining
>>> job.proxydb updated
[4]:
# load observations
# URL: https://atmos.washington.edu/~rtardif/LMR/prior/tas_sfc_Amon_iCESM_past1000historical_085001-200512.nc
job.load_clim(
tag='obs',
path_dict={
'tas': 'iCESM_past1000historical/tas',
},
anom_period=(1951, 1980),
verbose=True,
)
>>> job.configs["obs_path"] = {'tas': 'iCESM_past1000historical/tas'}
>>> job.configs["obs_anom_period"] = [1951, 1980]
>>> job.configs["obs_lat_name"] = lat
>>> job.configs["obs_lon_name"] = lon
>>> job.configs["obs_time_name"] = time
>>> The target file seems existed at: ./data/tas_sfc_Amon_iCESM_past1000historical_085001-200512.nc . Loading from it instead of downloading ...
>>> obs variables ['tas'] loaded
>>> job.obs created
[5]:
# regrid and crop obs to make the problem size smaller
job.regrid_clim(tag='obs', nlat=42, nlon=63, verbose=True)
job.crop_clim(tag='obs', lat_min=-20, lat_max=20, lon_min=150, lon_max=260, verbose=True)
>>> job.configs["obs_regrid_nlat"] = 42
>>> job.configs["obs_regrid_nlon"] = 63
>>> Processing tas ...
>>> job.configs["obs_lat_min"] = -20
>>> job.configs["obs_lat_max"] = 20
>>> job.configs["obs_lon_min"] = 150
>>> job.configs["obs_lon_max"] = 260
>>> Processing tas ...
[6]:
# annualize the observations
job.annualize_clim(tag='obs', verbose=True, months=[12, 1, 2])
>>> job.configs["obs_annualize_months"] = [12, 1, 2]
>>> Processing tas ...
>>> job.obs updated
Graph estimation#
In GraphEM, the selection of the covariance model used for inferring missing values is based on a graph. Two types of graphs are supported:
Neighborhood graphs
Empirical graphs (graphical lasso)
Neighborhoood graphs as implemented here depend on a single parameter, the cutoff radius \(R_c\). Every grid point or proxy within a great circle distance \(R_c\) of a given grid point or proxy is declared a “neighbor”, and the adjency matrix betweens those two points \((i,j)\) is \(A_{ij} = A_{ji} = 1\) (it is 0 otherwise). The graphical lasso is a much more complicated, data-driven method that pulls conditional independence relations between variables from the data themselves, resulting in much more realistic covariance estimation that can detect coastlines, mountain ranges, currents or teleconnection patterns. While a neighborhood graph can always be specified, that is not the case for the graphical lasso: in our implementation it can only be applied to a gap-free data matrix. We recommend using a neighborhood graph \(G_{R_c}\) with GraphEM to fill the gaps in the data matrix, then apply the graphical lasso to this clean matrix over the instrumental interval to estimate the graph \(G_L\). Then, the GraphEM reconstruction can proceed with \(G_L\).
However, the difficulty is that both types of graph are controlled by a parameter whose value is uncertain. For neighborhood graphs, an overly generous \(R_c\) will lead to an under-regularized the model, with too many variables \(p\) to estimate relative to the number of samples \(n\) ; this will yield a numerically unstable solution that may fail to converge. On the other hand, if \(R_c\) is too small, \(A\) is too sparse, the model is over-regularized and the solution very damped. In the limit of \(R_c=0\), \(A\) is the identity matrix and the reconstruction is a flatline.
What then is the optimal choice? Unfortunately, there is no theoretical criterion on how to choose an appropriate one. At a minimum, it should be larger than the largest spacing between nearby grid points (which tends to be largest at the equator). At most, it should be the circumference of the planet. That leaves quite some room in between. We will first carry out a preliminary reconstruction, before refining the choice of cutoff-radius via a process called cross-validation.
In the second section, we will do the same for the graphical lasso to choose an optimal combination of sparsity parameters.
1a) Cross-validation#
For this exercise we will use the same terminology as scikit-learn. Cross-validation is fundamental to model fitting, and is the most time-tested way to tune the parameters of a regression model such as GraphEM. Indeed, we can fit any graph to the data. The graph we want is the one that gives the “best” result. Best is in quotes because it may not always be possible to locate a unique optimum, so we may need to add other considerations.
There are various flavors of cross-validation one can use. k-fold cross-validation (typically with \(k=5\)) is a popular choice and what GraphEM implements (note: we could use the same approach to choose the localization radius in DA). This is what it looks like: the data are split in 5 groups. In each group, one withhold \(1/k\) of the data for validation, using the remaining \((k-1)/k\) for calibration.
[8]:
from IPython.display import Image
from IPython.core.display import HTML
Image(url= "https://scikit-learn.org/stable/_images/grid_search_cross_validation.png", width=600, height=400)
[8]:

This process is repeated for various values of the tuning parameter (here, the cutoff radius) to construct a curve of some measure of expected prediction error (e.g. the mean square error, or MSE) vs the cutoff radius. That curve should have a U-shape, and the goal is to find the value of R that minimizes it. TO do so, we use the module graphem_kcv(), looping over a vector of cutoff radii for the neighborhood graph. One difficulty lies in specifying appropriate bounds for this search:
numerically, the algorithm will always converge for a very small radius (though the solution will be overregularized, hence very damped in amplitude). At the other end of the spectrum, for large radii the solution is under-regularized, hence numerically unstable. The practical consequence is that GraphEM will fail to converge and throw many error messages along the way. Here we choose to search a space spanning 500 to 5000km in increments of 500km, but finding the upper bound can require some
trial and error.
[11]:
%%time
job_neigh = job.copy()
# cross validation test
cutoff_radii=np.arange(start=1000,stop=2001,step=500)
kcv_res = job_neigh.graphem_kcv(
cv_time=np.arange(1850, 2001), stat='MSE', n_splits=5,
ctrl_params=cutoff_radii,
graph_type='neighborhood',
)
>>> Processing fold 1:
>>> parameter = 1000
Centering each of the ProxyRecord: 100%|██████████| 49/49 [00:00<00:00, 1811.46it/s]
EM | dXmis: 0.0026; rdXmis: 0.0038: 4%|▍ | 9/200 [03:55<1:23:11, 26.13s/it]
GraphEM.EM(): Tolerance achieved.
>>> parameter = 1500
Centering each of the ProxyRecord: 100%|██████████| 49/49 [00:00<00:00, 1102.18it/s]
EM | dXmis: 0.0045; rdXmis: 0.0070: 17%|█▋ | 34/200 [42:55<3:29:35, 75.76s/it]
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
File <timed exec>:5
File ~/Github/cfr/cfr/reconjob.py:977, in ReconJob.graphem_kcv(self, cv_time, ctrl_params, graph_type, stat, n_splits)
974 adjs[(i+1, param)] = g_cv
976 # run graphem with this graph
--> 977 j_cv.run_graphem(
978 save_recon=False,
979 verbose=False,
980 estimate_graph=False,
981 graph=g_cv.adj)
983 # compute verification statistics
984 field_r = j_cv.graphem_solver.field_r
File ~/Github/cfr/cfr/reconjob.py:1045, in ReconJob.run_graphem(self, save_recon, save_dirpath, save_filename, load_precalc_solver, solver_save_path, compress_params, verbose, output_indices, **fit_kws)
1043 fit_kwargs.update(fit_kws)
1044 if fit_kwargs['graph_method'] in ['neighborhood', 'glasso']:
-> 1045 self.graphem_solver.fit(
1046 self.graphem_params['field'],
1047 self.graphem_params['proxy'],
1048 self.graphem_params['calib_idx'],
1049 verbose=verbose,
1050 **fit_kwargs)
1051 elif fit_kwargs['graph_method'] == 'hybrid':
1052 fit_kwargs.update({'graph_method': 'neighborhood'})
File ~/Github/cfr-graphem/graphem/solver.py:139, in GraphEM.fit(self, field, proxy, calib, graph, lonlat, sp_FF, sp_FP, sp_PP, N_graph, C0, M0, maxit, bootstrap, N_boot, cutoff_radius, graph_method, estimate_graph, save_graphs, verbose)
136 else:
137 if verbose: print("Using specified graph")
--> 139 [X,C,M] = self.EM(X, self.graph, C0, M0, maxit, verbose=verbose)
140 self.field_r = X[:,ind_F]
141 self.proxy_r = X[:,ind_P]
File ~/Github/cfr-graphem/graphem/solver.py:240, in GraphEM.EM(self, X, graph, C0, M0, maxit, use_iridge, verbose)
238 B, S, __, __ = iridge.iridge(C, avlr, misr, n-1)
239 else:
--> 240 B, S = ols(C, avlr, misr)
241 ind_obs = find(pattern_ix == i1)
242 mp = len(ind_obs) # Number of rows matching current pattern
File ~/Github/cfr-graphem/graphem/solver.py:536, in ols(Sigma, xind, yind)
516 def ols(Sigma, xind, yind):
517 '''
518 Computes regression coefficients in a multivariate Gaussian model
519
(...)
534 Covariance of the residuals
535 '''
--> 536 B = linalg.inv(Sigma[np.ix_(xind,xind)]).dot(Sigma[np.ix_(xind,yind)])
537 S = Sigma[np.ix_(yind,yind)] - Sigma[np.ix_(yind, xind)].dot(B)
538 return [B, S]
File ~/Apps/miniconda3/envs/cfr-env/lib/python3.9/site-packages/scipy/linalg/_basic.py:962, in inv(a, overwrite_a, check_finite)
950 # XXX: I found no advantage or disadvantage of using finv.
951 # finv, = get_flinalg_funcs(('inv',),(a1,))
952 # if finv is not None:
(...)
957 # if info<0: raise ValueError('illegal value in %d-th argument of '
958 # 'internal inv.getrf|getri'%(-info))
959 getrf, getri, getri_lwork = get_lapack_funcs(('getrf', 'getri',
960 'getri_lwork'),
961 (a1,))
--> 962 lu, piv, info = getrf(a1, overwrite_a=overwrite_a)
963 if info == 0:
964 lwork = _compute_lwork(getri_lwork, a1.shape[0])
KeyboardInterrupt:
[28]:
len(kcv_res.adjs)
[28]:
15
[31]:
fig, ax = kcv_res.plot_adjs()

[25]:
fig, ax = kcv_res.plot()
Minimum reached for R = 2000 km.
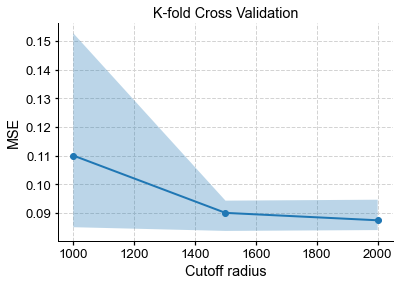
This shows the familiar U-shape mentioned above, and the cutoff radius that appears to minimize the MSE averaged over the 5 folds is 2000 km. However, you might notice that this minimum is rather shallow, so there is no strong reason to prefer this value over 1500 or 2500 km. However, there is an informal principle, known as the “1-SD rule”, which states that in situations like these, one wants to select the least complex model whose MSE is within 1 standard deviation (fold-wise) of the global minimum. It looks from the plot that the least complex model (in this case, the one with sparsest graph, hence smallest cutoff radius), is the one corresponding to R = 1500 km. Indeed:
[33]:
optimal_radius = kcv_res.one_sd_rule()
# optimal_radius = 1500 # shortcut
The 1SD rule selects R = 1500 km.
We must caution that the 1SD rule is a bit like statistical folklore: in wide use but without strong theoretical justification. Nevertheless, we have found it to yield fairly reliable results.
1b Reconstruction#
Now that we have objectively chosen the graph, we can use the method prep_graphem() to weave everything into an object that the code can work with:
[34]:
job_neigh.prep_graphem(
recon_period=(1001, 2000),
calib_period=(1850, 2000),
verbose=True)
>>> job.configs["recon_period"] = (1001, 2000)
>>> job.configs["recon_timescale"] = 1
>>> job.configs["calib_period"] = (1850, 2000)
>>> job.graphem_params["recon_time"] created
>>> job.graphem_params["calib_time"] created
>>> job.graphem_params["field_obs"] created
>>> job.graphem_params["calib_idx"] created
>>> job.graphem_params["field"] created
>>> job.graphem_params["df_proxy"] created
>>> job.graphem_params["proxy"] created
>>> job.graphem_params["lonlat"] created
[35]:
job_neigh.graphem_params['field']
[35]:
array([[ nan, nan, nan, ..., nan, nan,
nan],
[ nan, nan, nan, ..., nan, nan,
nan],
[ nan, nan, nan, ..., nan, nan,
nan],
...,
[0.70970161, 0.73450522, 0.30319882, ..., 0.34267614, 0.25509715,
0.39273508],
[0.57543254, 0.4847614 , 0.17716476, ..., 0.26505406, 0.25998264,
0.37178005],
[0.66133266, 0.97367383, 1.02246066, ..., 0.0466115 , 0.12031657,
0.13679344]])
[36]:
job_neigh.graphem_params['df_proxy']
[36]:
| Ocn_065 | Ocn_075 | Ocn_078 | Ocn_167 | Ocn_091 | Ocn_093 | Ocn_096 | Ocn_086 | Ocn_101 | Ocn_070 | ... | Ocn_090 | Ocn_119 | Ocn_109 | Ocn_097 | Ocn_159 | Ocn_087 | Ocn_153 | Ocn_169 | Ocn_071 | Ocn_072 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1001 | -0.029472 | -0.079615 | -0.164675 | 1.136972 | -0.170487 | -0.068706 | 0.001636 | 0.265989 | 0.029111 | -0.060844 | ... | -0.016145 | -0.023198 | 0.026751 | -0.290637 | -0.036539 | -0.121053 | -0.043656 | -0.082111 | -0.135477 | -0.098504 |
| 1002 | -0.021149 | -0.096633 | -0.120066 | 0.211940 | -0.247028 | -0.053001 | 0.014841 | -0.099275 | -0.163322 | -0.069958 | ... | -0.651486 | -0.012971 | -0.026148 | -0.209297 | 0.015105 | 0.072593 | -0.088941 | 0.132871 | -0.066113 | -0.025315 |
| 1003 | 0.017044 | 0.177338 | 0.067678 | -0.201700 | 0.062675 | 0.001354 | 0.009087 | 0.010825 | 0.001898 | -0.107092 | ... | -0.184804 | -0.250715 | -0.002932 | 0.198525 | -0.043845 | 0.095773 | 0.076952 | 0.905556 | -0.117440 | 0.068865 |
| 1004 | -0.072836 | 0.050557 | -0.047072 | -0.452527 | -0.251116 | 0.059971 | 0.044815 | 0.041075 | 0.088916 | -0.177990 | ... | -0.192031 | -0.190020 | 0.028051 | 0.091881 | -0.070303 | 0.038124 | -0.014257 | 0.104113 | 0.022662 | -0.027317 |
| 1005 | 0.036772 | -0.181680 | 0.057200 | -0.042987 | 0.042531 | 0.017662 | -0.011964 | -0.014553 | -0.036732 | 0.045409 | ... | 0.136227 | -0.204292 | -0.041819 | -0.188765 | -0.051463 | -0.252486 | 0.095564 | -0.581049 | -0.271404 | 0.033542 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1996 | 0.084822 | 0.202729 | 0.237921 | -0.680074 | -0.085530 | 0.000029 | -0.077145 | -0.059342 | 0.055956 | 0.283716 | ... | 0.096534 | 0.287984 | -0.026136 | 0.299611 | 0.096891 | -0.002844 | 0.072604 | 0.326452 | -0.042538 | 0.036153 |
| 1997 | 0.062888 | 0.627227 | 0.257458 | 0.895186 | 0.445891 | 0.036438 | 0.011253 | 0.408338 | 0.012960 | 0.111141 | ... | 0.227277 | -0.044239 | 0.068132 | 0.145206 | -0.044438 | -0.251896 | 0.106174 | 0.265856 | -0.095977 | -0.026760 |
| 1998 | 0.081860 | 0.218101 | 0.092819 | -2.040758 | 0.530765 | 0.046501 | 0.162912 | 0.195244 | 0.074552 | 0.075628 | ... | 0.248375 | 0.137352 | 0.128556 | 0.252945 | 0.006005 | 0.192609 | 0.046924 | 0.344340 | -0.018421 | 0.002962 |
| 1999 | 0.053651 | -0.316188 | 0.131558 | 0.182525 | -0.043207 | 0.080396 | -0.022788 | 0.234294 | 0.170416 | 0.076104 | ... | 0.071616 | 0.122794 | -0.010480 | 0.271125 | 0.021608 | -0.088485 | -0.014478 | 1.077392 | 0.440469 | 0.000934 |
| 2000 | 0.032117 | -0.051677 | 0.036500 | -0.046688 | 0.192880 | 0.004209 | -0.030575 | 0.142909 | 0.096593 | 0.189709 | ... | 0.369924 | -0.111834 | 0.053092 | 0.554461 | 0.064681 | 0.075846 | 0.167034 | 0.317662 | 0.241359 | 0.041970 |
1000 rows × 104 columns
[37]:
G_R = cfr.graphem.Graph(
job_neigh.graphem_params['lonlat'],
job_neigh.graphem_params['field'],
job_neigh.graphem_params['proxy'])
Let us define a neighborhood graph by including only points within a cutoff_radius \(R\) of each grid point or proxy locale. The location takes a bit of time the first time around as the matrix of mutual great- circle distances needs to be computed:
[38]:
G_R.neigh_adj(cutoff_radius=optimal_radius)
Next we plot the temperature neighbors of a particular proxy to show what happened:
[39]:
n_proxy = job_neigh.graphem_params['df_proxy'].shape[1]
idcs = np.random.randint(0,n_proxy,4) # randomly pick indices
fig = plt.figure(figsize=(10, 10))
gs = gridspec.GridSpec(2, 2)
gs.update(wspace=0.2, hspace=0.2)
ax = {}
for i, idx in enumerate(idcs):
fig_map, ax_map = G_R.plot_neighbors(idx)
cfr.closefig(fig_map) # mute the figure
ax[idx] = fig.add_subplot(gs[i], projection=ax_map.projection)
G_R.plot_neighbors(idx,ax=ax[idx])
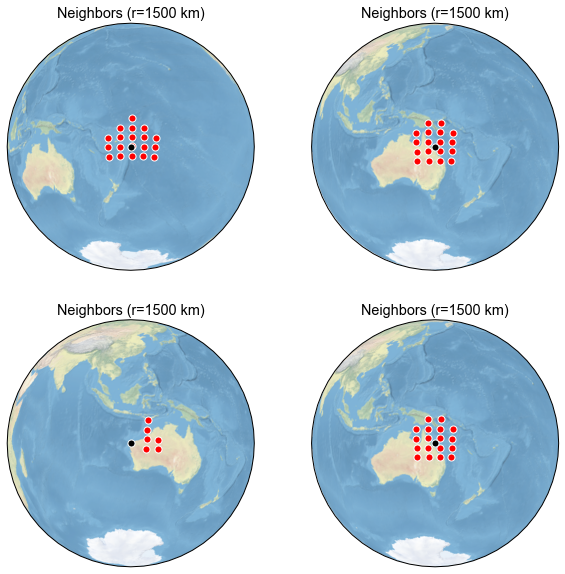
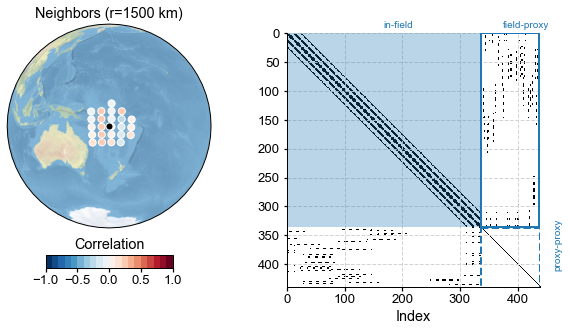
This, however, does not tell us the degree to which this proxy correlates to temperature at nerby grid points over the instrumental era. To do that, we use:
[24]:
G_R.plot_neighbors_corr(idcs[2])
[24]:
(<Figure size 360x360 with 2 Axes>,
<GeoAxesSubplot:title={'center':'Neighbors (r=1500 km)'}>)
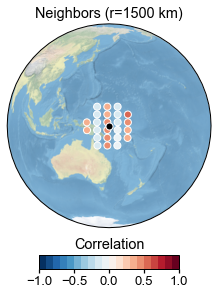
This can be instructive for small proxy networks, or for debugging purposes. For instance, we notice one proxy in the tropical Atlantic that has zero neighbors, because the grid is restricted to the Pacific far beyond the cutoff radius.
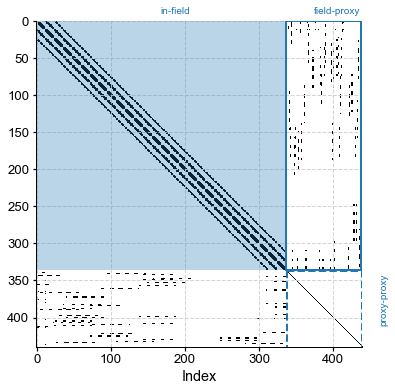
For a bird’s eye view of the graph, we instead plot the adjacency matrix itself (dots indicate neighbors):
[25]:
G_R.plot_adj()
[25]:
(<Figure size 432x432 with 1 Axes>, <AxesSubplot:xlabel='Index'>)
[26]:
# an example of passing axes with map projections
# we need to first make a plot with map projections to get the specific projection,
# otherwise we have ot set it manually later
i = 20 # proxy index
fig_map, ax_map = G_R.plot_neighbors(i)
cfr.closefig(fig_map) # mute the figure
# now we make a new figure to include subplots generated by
# `plot_neighbors()` or `plot_neighbors_corr()` and `plot_adj()`
fig = plt.figure(figsize=[10, 5])
ax = {}
gs = gridspec.GridSpec(1, 2)
gs.update(wspace=0.2, hspace=0.2)
# the 1st subplot will use the exact projection we had earlier
ax['map'] = fig.add_subplot(gs[0], projection=ax_map.projection)
ax['adj'] = fig.add_subplot(gs[1])
# we may call `plot_neighbors_corr()` since it has the same projection
ax['map'] = G_R.plot_neighbors_corr(i, ax=ax['map'])
ax['adj'] = G_R.plot_adj(ax=ax['adj'])
By construction, proxies are assumed conditionally independent of each other, so the proxy-proxy part of the adjacency matrix is diagonal. The climate-climate is block-diagonal, reflecting the fact that nearby indices tend to reflect nearby gridpoints, and nearby gridpoints generally have similar climates*. There are discontinuities that happen when cycling through longitudes (0 –> 360 back to 0), which show up as abrupt breaks in the graph. The climate-proxy part is less regular, reflecting
the fact that proxy locations are not uniformly spaced (unlike the grid points of the climate field). Notice how the overall matrix is very sparse: only a handful of of entries are non-zero (white is the main color on this plot). To be more precise, the sparsity property quantifies the fraction of non-zero entries:
[27]:
G_R.sparsity
[27]:
[0.05653873489694385, 0.03345352564102564, 0.0]
We see that only a few % of the graph of the climate field and of the climate-proxy graph, have non-zero entries (the diagonal is excluded from this calculation, because a random variable is always conditionally dependent on itself). With this convention, and assuming that proxies are independent of each other (corals from two different islands don’t affect each other’s growth, given the climate). then the proxy-proxy part of the adjacency matrix is diagonal and has a sparsity of 0. This graph has achieved what we wanted: reducing the number of parameters to be estimated while computing the covariance matrix, which otherwise would be ill-conditioned.
running GraphEM#
[28]:
job_neigh.run_graphem?
Signature:
job.run_graphem(
save_recon=True,
save_dirpath=None,
load_precalc_solver=False,
solver_save_path=None,
compress_params=None,
verbose=False,
**fit_kws,
)
Docstring:
Run the GraphEM solver, essentially the :py:meth: `GraphEM.solver.GraphEM.fit` method
Note that the arguments for :py:meth: `GraphEM.solver.GraphEM.fit` can be appended in the
argument list of this function directly. For instance, to pass a pre-calculated graph, use
`estimate_graph=False` and `graph=g.adj`, where `g` is the :py:`Graph` object.
Args:
save_dirpath (str): the path to save the related results
load_precalculated (bool, optional): load the precalculated `Graph` object. Defaults to False.
verbose (bool, optional): print verbose information. Defaults to False.
fit_kws (dict): the arguments for :py:meth: `GraphEM.solver.GraphEM.fit`
See also:
cfr.graphem.solver.GraphEM.fit : fitting the GraphEM method
File: ~/Documents/GitHub/cfr/cfr/reconjob.py
Type: method
[77]:
%%time
job_neigh.run_graphem(
save_recon=True,
save_dirpath='./results/graphem-ppe-pages2k',
verbose=True,
estimate_graph=False,
graph=G_R.adj,
)
>>> job.configs["save_dirpath"] = ./results/graphem-ppe-pages2k
Using specified graph
Running GraphEM:
Iter dXmis rdXmis
001 0.0498 0.7232
002 0.1861 2.1704
003 0.0904 0.3866
004 0.0495 0.1568
005 0.0325 0.0928
006 0.0238 0.0639
007 0.0201 0.0516
008 0.0177 0.0439
009 0.0163 0.0393
010 0.0147 0.0346
011 0.0138 0.0319
012 0.0125 0.0284
013 0.0116 0.0259
014 0.0112 0.0248
015 0.0103 0.0225
016 0.0102 0.0221
017 0.0094 0.0201
018 0.0088 0.0188
019 0.0089 0.0190
020 0.0082 0.0173
021 0.0077 0.0161
022 0.0072 0.0152
023 0.0075 0.0157
024 0.0069 0.0143
025 0.0064 0.0133
026 0.0060 0.0124
027 0.0057 0.0117
028 0.0053 0.0110
029 0.0051 0.0104
030 0.0048 0.0099
031 0.0054 0.0111
032 0.0042 0.0086
033 0.0048 0.0098
034 0.0043 0.0088
035 0.0040 0.0081
036 0.0037 0.0076
037 0.0035 0.0072
038 0.0033 0.0067
039 0.0031 0.0064
040 0.0030 0.0060
041 0.0028 0.0057
042 0.0026 0.0054
043 0.0025 0.0051
044 0.0024 0.0048
job.graphem_solver created and saved to: None
>>> job.recon_fields created
>>> Reconstructed fields saved to: ./results/graphem-ppe-pages2k/job_r01_recon.nc
CPU times: user 4min 55s, sys: 16.5 s, total: 5min 12s
Wall time: 20.9 s
1.c Validation#
Now we have a reconstruction ; let’s see how well it compares to the target:
[78]:
neigh_res = cfr.ReconRes('./results/graphem-ppe-pages2k', verbose=True)
>>> res.paths:
['./results/graphem-ppe-pages2k/job_r01_recon.nc']
[79]:
neigh_res.load(['nino3.4', 'tas'], verbose=True)
>>> ReconRes.recons["nino3.4"] created
>>> ReconRes.da["nino3.4"] created
>>> ReconRes.recons["tas"] created
>>> ReconRes.da["tas"] created
[80]:
mask = (job_neigh.obs['tas'].time >= 1001) & (job_neigh.obs['tas'].time <= 2000)
target = job_neigh.obs['tas'].da.values[mask]
print(np.shape(target))
(1000, 12, 28)
Spatially-averaged Statistics#
[81]:
nt = np.size(neigh_res.recons['tas'].time)
field_r = job_neigh.graphem_solver.field_r
inst = job_neigh.graphem_params['calib_idx']
V = cfr.graphem.solver.verif_stats(field_r, target.reshape((nt, -1)), inst)
print(V)
Mean MSE = 0.1018, Mean RE = 0.5506, Mean CE = 0.4918, Mean R2 = 0.5691
Map of CE#
[82]:
ce = cfr.utils.coefficient_efficiency(target, neigh_res.recons['tas'].da.values)
print(np.shape(ce))
(12, 28)
[83]:
import seaborn as sns
import cartopy.crs as ccrs
import cartopy.feature as cfeature
from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter
fig = plt.figure(figsize=[8, 8])
ax = plt.subplot(projection=ccrs.PlateCarree(central_longitude=180))
ax.set_title('Coefficient of Efficiency')
# latlon_range = [0, 360, -90, 90]
latlon_range = [122, 278, -25, 25]
transform=ccrs.PlateCarree()
ax.set_extent(latlon_range, crs=transform)
lon_formatter = LongitudeFormatter(zero_direction_label=False)
lat_formatter = LatitudeFormatter()
ax.xaxis.set_major_formatter(lon_formatter)
ax.yaxis.set_major_formatter(lat_formatter)
lon_ticks=[60, 120, 180, 240, 300]
lat_ticks=[-90, -45, 0, 45, 90]
lon_ticks = np.array(lon_ticks)
lat_ticks = np.array(lat_ticks)
lon_min, lon_max, lat_min, lat_max = latlon_range
mask_lon = (lon_ticks >= lon_min) & (lon_ticks <= lon_max)
mask_lat = (lat_ticks >= lat_min) & (lat_ticks <= lat_max)
ax.set_xticks(lon_ticks[mask_lon], crs=ccrs.PlateCarree())
ax.set_yticks(lat_ticks[mask_lat], crs=ccrs.PlateCarree())
levels = np.linspace(-1, 1, 21)
cbar_labels = np.linspace(-1, 1, 11)
cbar_title = 'CE'
extend = 'both'
cmap = 'RdBu_r'
cbar_pad=0.1
cbar_orientation='horizontal'
cbar_aspect=10
cbar_fraction=0.35
cbar_shrink=0.8
font_scale=1.5
land_color=sns.xkcd_rgb['light grey']
ocean_color=sns.xkcd_rgb['white']
ax.add_feature(cfeature.LAND, facecolor=land_color, edgecolor=land_color)
ax.add_feature(cfeature.OCEAN, facecolor=ocean_color, edgecolor=ocean_color)
ax.coastlines()
im = ax.contourf(job_neigh.obs['tas'].lon, job_neigh.obs['tas'].lat, ce, levels, transform=transform, cmap=cmap, extend=extend)
cbar = fig.colorbar(
im, ax=ax, orientation=cbar_orientation, pad=cbar_pad, aspect=cbar_aspect,
fraction=cbar_fraction, shrink=cbar_shrink)
cbar.set_ticks(cbar_labels)
cbar.ax.set_title(cbar_title)
[83]:
Text(0.5, 1.0, 'CE')

Timeseries comparison#
[84]:
da = cfr.utils.geo_mean(job_neigh.obs['tas'].da, lat_min=-5, lat_max=5, lon_min=np.mod(-170, 360), lon_max=np.mod(-120, 360))
ref_time = da.year.values
ref_value = da.values
ref_name = 'truth'
[85]:
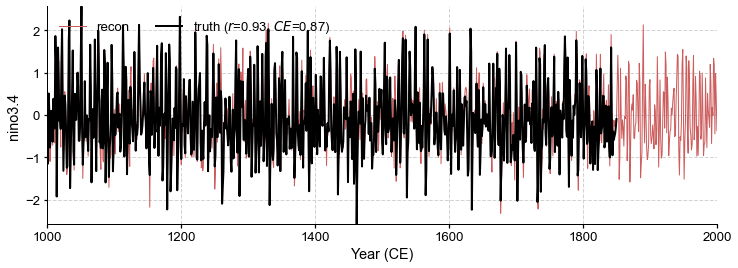
fig, ax = neigh_res.recons['nino3.4'].validate(
ref_time, ref_value, ref_name, valid_period=[1001, 1850]).plot()
ax.set_xlim(1000, 2000)
[85]:
(1000.0, 2000.0)
[41]:
lats, lons, colors, markers, markersizes = {}, {}, {}, {}, {}
for pobj in job.proxydb:
pid = pobj.pid
lats[pid] = pobj.lat
lons[pid] = pobj.lon
colors[pid] = cfr.visual.STYLE.colors_dict[pobj.ptype]
markers[pid] = cfr.visual.STYLE.markers_dict[pobj.ptype]
markersizes[pid] = 200
[86]:
stat = 'CE' # Bug: colorbad shows R2 instead of CE
neigh_valid = neigh_res.recons['tas'].validate(
job.obs['tas'], stat=stat,
valid_period=(1750, 1850),
interp_direction='from-ref',
)
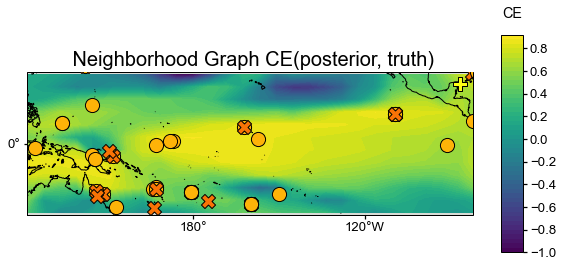
fig, ax = neigh_valid.plot(
title=f'{stat}(posterior, truth)',
projection='PlateCarree',
latlon_range=(-25, 25, 122, 278),
site_lats=lats, site_lons=lons,
site_markersize=markersizes, site_marker=markers,
site_color=colors,
**valid_fd.plot_kwargs)
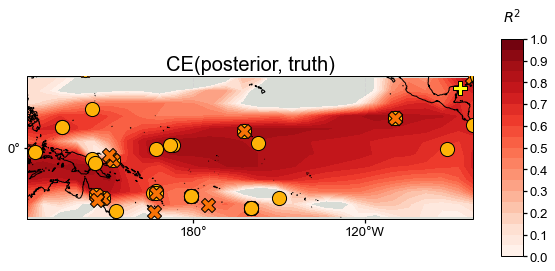
We see that skill is very high in most regions, particularly in the vicinity of proxy sites, though the SPCZ is less well captured than the central equatorial Pacific, for instance.
2. Graphical Lasso#
The graphical LASSO (Friedman et al, 2008) is a convex optimization algorithm that uses least angles regression to obtain the adjacency matrix.
In GraphEM, GLASSO is controlled by 2 sparsity parameters:
target_FF: Target sparsity of the in-field part of the graph (%)
target_FP: Target sparsity of the field/proxy part of the graph (%)
As before, the sparser the graph, the fewer variables are estimated, and the better conditioned the covariance matrices are, but a good compromise must be found so as not to over-regularize. As a rule of thumb, target sparsities should be on the order of a few % (1-10) to give reasonable results. Let us first look at the case where these numbers are 3% and 3%, respectively:
2a. Greedy Search#
The code uses a greedy algorithm to obtain a graph whose sparsity approaches that of the target:
[43]:
G_L = cfr.graphem.Graph(
lonlat = job.graphem_params['lonlat'],
field = field_r[inst],
proxy = job.graphem_params['proxy'][inst,:])
[50]:
G_L.glasso_adj(target_FF=3,target_FP=4)
Solving graphical LASSO using greedy search
Iter FF FP PP
001 0.000 0.000 0.000
002 0.867 0.000 0.000
003 2.347 0.000 0.000
004 3.746 0.000 0.000
005 3.746 0.000 0.000
006 3.746 0.000 0.000
007 3.746 0.000 0.000
008 3.746 0.000 0.000
009 3.746 0.000 0.000
010 3.746 0.103 0.000
011 3.746 0.358 0.000
012 3.730 0.793 0.000
013 3.669 1.540 0.000
014 3.502 2.802 0.000
015 3.129 4.006 0.000
[51]:
G_L.sparsity
[51]:
array([3.5021322 , 2.80162546, 0. ])
[46]:
fig, ax = plt.subplots(1,2,figsize=(10,5))
plt.tight_layout()
plt.subplots_adjust(wspace=0.2)
G_R.plot_adj(ax=ax[0],clr='C0')
ax[0].set_title("Optimal neighborhood graph") # need to fix vertical spacing
G_L.plot_adj(ax=ax[1],clr='C1')
ax[1].set_title("Tentative GLASSO graph, sp = {:3.2f} %".format(G_L.sparsity[0],G_L.sparsity[1]))
[46]:
Text(0.5, 1.0, 'Tentative GLASSO graph, sp = 3.50 %')
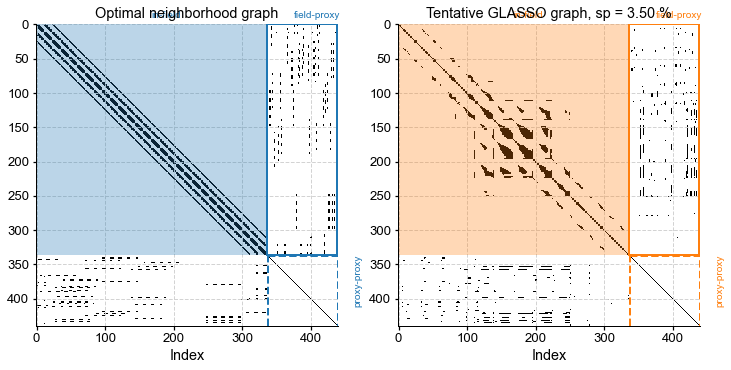
Comparing with the previously obtained neighborhood graph, we see that GLASSO, for this particular choice of parameters, led to a similar block-diagonal pattern for the in-field part of the matrix, however the extent of these blocks varies from point to point. This is an indication of anisotopy: the algorithm is able to detect coherent structures that may be irregular in latitude and longitude. Let’s look at those neighbors:
[47]:
n_grid = field_r.shape[1]
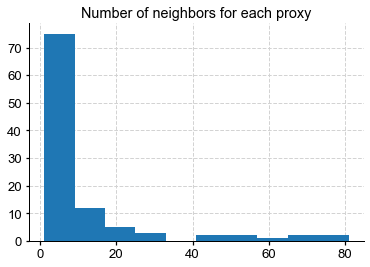
n_neighbors = np.sum(G_L.adj[n_grid:,:],axis=1)
plt.hist(n_neighbors)
plt.title("Number of neighbors for each proxy")
[47]:
Text(0.5, 1.0, 'Number of neighbors for each proxy')
[ ]:
rich_proxies = np.where(n_neighbors>20)[0]
four_idcs = np.random.randint(0,len(rich_proxies),4)
glasso_idcs = rich_proxies[four_idcs]
fig = plt.figure(figsize=(10, 10))
gs = gridspec.GridSpec(2, 2)
gs.update(wspace=0.2, hspace=0.2)
ax = {}
for i, idx in enumerate(glasso_idcs):
fig_map, ax_map = G_L.plot_neighbors(idx)
cfr.closefig(fig_map) # mute the figure
ax[idx] = fig.add_subplot(gs[i], projection=ax_map.projection)
G_L.plot_neighbors(idx,ax=ax[idx])
We see that some proxies are deemed important by GLASSO, which finds them many neighbors in the climate field. Put another way, those proxies will inform the reconstruction of the climate field at the location of these red dots, though not in equal amount (they will be weighted by covariances, not shown here).
Now, as before, we must optimize to find parameters that maxmimize reconstruction skill.
2b. Cross-Validation#
[53]:
%%time
# cross validation test
sp_vec = np.arange(1.0,9.0)
kcv_stats = job.graphem_kcv(
cv_time = np.arange(1850, 2001), stat='MSE', n_splits=5,
ctrl_params = sp_vec, graph_type = 'glasso'
)
>>> Processing fold 1:
>>> parameter = 1.0
Unexpected exception formatting exception. Falling back to standard exception
Traceback (most recent call last):
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/IPython/core/magics/execution.py", line 1316, in time
exec(code, glob, local_ns)
File "<timed exec>", line 3, in <module>
File "/Users/julieneg/Documents/GitHub/cfr/cfr/reconjob.py", line 860, in graphem_kcv
g_cv.glasso_adj(target_FF=param, target_FP=param)
File "/Users/julieneg/Documents/GitHub/cfr/cfr/graphem/graph.py", line 135, in glasso_adj
[adj, sp] = graph_greedy_search(self.field, self.proxy, target_FF, target_FP)
ValueError: too many values to unpack (expected 2)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/IPython/core/interactiveshell.py", line 1993, in showtraceback
stb = self.InteractiveTB.structured_traceback(
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/IPython/core/ultratb.py", line 1118, in structured_traceback
return FormattedTB.structured_traceback(
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/IPython/core/ultratb.py", line 1012, in structured_traceback
return VerboseTB.structured_traceback(
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/IPython/core/ultratb.py", line 865, in structured_traceback
formatted_exception = self.format_exception_as_a_whole(etype, evalue, etb, number_of_lines_of_context,
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/IPython/core/ultratb.py", line 818, in format_exception_as_a_whole
frames.append(self.format_record(r))
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/IPython/core/ultratb.py", line 736, in format_record
result += ''.join(_format_traceback_lines(frame_info.lines, Colors, self.has_colors, lvals))
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/stack_data/utils.py", line 145, in cached_property_wrapper
value = obj.__dict__[self.func.__name__] = self.func(obj)
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/stack_data/core.py", line 698, in lines
pieces = self.included_pieces
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/stack_data/utils.py", line 145, in cached_property_wrapper
value = obj.__dict__[self.func.__name__] = self.func(obj)
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/stack_data/core.py", line 649, in included_pieces
pos = scope_pieces.index(self.executing_piece)
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/stack_data/utils.py", line 145, in cached_property_wrapper
value = obj.__dict__[self.func.__name__] = self.func(obj)
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/stack_data/core.py", line 628, in executing_piece
return only(
File "/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/executing/executing.py", line 164, in only
raise NotOneValueFound('Expected one value, found 0')
executing.executing.NotOneValueFound: Expected one value, found 0
2c. Reconstruction#
[55]:
job_glasso = job.copy()
job_glasso.run_graphem(
save_recon=True,
save_dirpath='./results/graphem-ppe-pages2k',
verbose=True,
estimate_graph=False,
graph=G_L.adj,
)
>>> job.configs["save_dirpath"] = ./results/graphem-ppe-pages2k
Using specified graph
Running GraphEM:
Iter dXmis rdXmis
001 0.0498 0.7232
002 0.2066 2.4095
003 0.0601 0.2358
004 0.0301 0.0989
005 0.0226 0.0696
006 0.0187 0.0552
007 0.0160 0.0459
008 0.0141 0.0393
009 0.0125 0.0340
010 0.0111 0.0297
011 0.0099 0.0262
012 0.0090 0.0235
013 0.0086 0.0222
014 0.0081 0.0207
015 0.0081 0.0206
016 0.0078 0.0197
017 0.0081 0.0204
018 0.0079 0.0198
019 0.0079 0.0195
020 0.0078 0.0193
021 0.0082 0.0202
022 0.0080 0.0194
023 0.0077 0.0187
024 0.0078 0.0189
025 0.0073 0.0175
026 0.0068 0.0163
027 0.0063 0.0151
028 0.0058 0.0139
029 0.0054 0.0127
030 0.0052 0.0123
031 0.0047 0.0110
032 0.0042 0.0099
033 0.0039 0.0091
034 0.0036 0.0083
035 0.0033 0.0076
036 0.0030 0.0070
037 0.0028 0.0065
038 0.0026 0.0060
039 0.0024 0.0055
040 0.0022 0.0051
041 0.0020 0.0047
job.graphem_solver created and saved to: None
>>> job.recon_fields created
>>> Reconstructed fields saved to: ./results/graphem-ppe-pages2k/job_r01_recon.nc
[56]:
glasso_res = cfr.ReconRes('./results/graphem-ppe-pages2k', verbose=True)
>>> res.paths:
['./results/graphem-ppe-pages2k/job_r01_recon.nc']
[57]:
glasso_res.load(['nino3.4', 'tas'], verbose=True)
>>> ReconRes.recons["nino3.4"] created
>>> ReconRes.da["nino3.4"] created
>>> ReconRes.recons["tas"] created
>>> ReconRes.da["tas"] created
Spatially-averaged Statistics#
[58]:
field_r = job_glasso.graphem_solver.field_r
inst = job_glasso.graphem_params['calib_idx']
V = cfr.graphem.solver.verif_stats(field_r, target.reshape((nt, -1)), inst)
print(V)
Mean MSE = 0.0953, Mean RE = 0.5975, Mean CE = 0.5423, Mean R2 = nan
/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/numpy/lib/function_base.py:2853: RuntimeWarning: invalid value encountered in divide
c /= stddev[:, None]
/Users/julieneg/opt/miniconda3/envs/cfr-env/lib/python3.9/site-packages/numpy/lib/function_base.py:2854: RuntimeWarning: invalid value encountered in divide
c /= stddev[None, :]
Map of CE#
[60]:
ce = cfr.utils.coefficient_efficiency(target, glasso_res.recons['tas'].da.values)
[61]:
fig = plt.figure(figsize=[8, 8])
ax = plt.subplot(projection=ccrs.PlateCarree(central_longitude=180))
ax.set_title('Coefficient of Efficiency')
# latlon_range = [0, 360, -90, 90]
latlon_range = [122, 278, -25, 25]
transform=ccrs.PlateCarree()
ax.set_extent(latlon_range, crs=transform)
lon_formatter = LongitudeFormatter(zero_direction_label=False)
lat_formatter = LatitudeFormatter()
ax.xaxis.set_major_formatter(lon_formatter)
ax.yaxis.set_major_formatter(lat_formatter)
lon_ticks=[60, 120, 180, 240, 300]
lat_ticks=[-90, -45, 0, 45, 90]
lon_ticks = np.array(lon_ticks)
lat_ticks = np.array(lat_ticks)
lon_min, lon_max, lat_min, lat_max = latlon_range
mask_lon = (lon_ticks >= lon_min) & (lon_ticks <= lon_max)
mask_lat = (lat_ticks >= lat_min) & (lat_ticks <= lat_max)
ax.set_xticks(lon_ticks[mask_lon], crs=ccrs.PlateCarree())
ax.set_yticks(lat_ticks[mask_lat], crs=ccrs.PlateCarree())
levels = np.linspace(-1, 1, 21)
cbar_labels = np.linspace(-1, 1, 11)
cbar_title = 'CE'
extend = 'both'
cmap = 'RdBu_r'
cbar_pad=0.1
cbar_orientation='horizontal'
cbar_aspect=10
cbar_fraction=0.35
cbar_shrink=0.8
font_scale=1.5
land_color=sns.xkcd_rgb['light grey']
ocean_color=sns.xkcd_rgb['white']
ax.add_feature(cfeature.LAND, facecolor=land_color, edgecolor=land_color)
ax.add_feature(cfeature.OCEAN, facecolor=ocean_color, edgecolor=ocean_color)
ax.coastlines()
im = ax.contourf(job.obs['tas'].lon, job.obs['tas'].lat, ce, levels, transform=transform, cmap=cmap, extend=extend)
cbar = fig.colorbar(
im, ax=ax, orientation=cbar_orientation, pad=cbar_pad, aspect=cbar_aspect,
fraction=cbar_fraction, shrink=cbar_shrink)
cbar.set_ticks(cbar_labels)
cbar.ax.set_title(cbar_title)
[61]:
Text(0.5, 1.0, 'CE')

Timeseries comparison#
[62]:
da = cfr.utils.geo_mean(job_glasso.obs['tas'].da, lat_min=-5, lat_max=5, lon_min=np.mod(-170, 360), lon_max=np.mod(-120, 360))
ref_time = da.year.values
ref_value = da.values
ref_name = 'truth'
[64]:
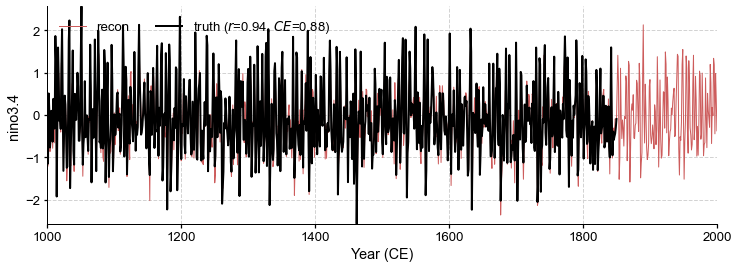
fig, ax = glasso_res.recons['nino3.4'].validate(
ref_time, ref_value, ref_name, valid_period=[1001, 1850]).plot()
ax.set_xlim(1000, 2000)
[64]:
(1000.0, 2000.0)
[41]:
lats, lons, colors, markers, markersizes = {}, {}, {}, {}, {}
for pobj in job.proxydb:
pid = pobj.pid
lats[pid] = pobj.lat
lons[pid] = pobj.lon
colors[pid] = cfr.visual.STYLE.colors_dict[pobj.ptype]
markers[pid] = cfr.visual.STYLE.markers_dict[pobj.ptype]
markersizes[pid] = 200
[90]:
stat = 'CE'
glasso_valid = glasso_res.recons['tas'].validate(
job.obs['tas'], stat=stat,
valid_period=(1750, 1850),
interp_direction='from-ref',
)
fig, ax = glasso_valid.plot(
title=f' Graphical LASSO {stat}(posterior, truth)',
projection='PlateCarree',
latlon_range=(-25, 25, 122, 278),
site_lats=lats, site_lons=lons,
site_markersize=markersizes, site_marker=markers,
site_color=colors)
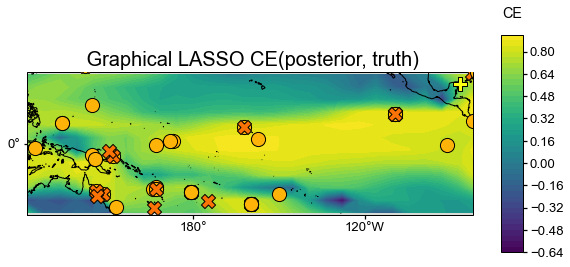
[89]:
fig, ax = neigh_valid.plot(
title=f' Neighborhood Graph {stat}(posterior, truth)',
projection='PlateCarree',
latlon_range=(-25, 25, 122, 278),
site_lats=lats, site_lons=lons,
site_markersize=markersizes, site_marker=markers,
site_color=colors)
How to easily compare two reconstructions pairwise? It would be nice to have a function called compare that takes neigh_res and glasso_res and compares the maps, timeseries, and tables of various metrics (R2, CE, etc.)
[ ]: